Le RAG expliqué : comment les chatbots IA apprennent réellement de la connaissance de votre entreprise
-
17 mars 2026
-
2004 Vues

Le RAG expliqué : comment les chatbots IA apprennent réellement de la connaissance de votre entreprise
La question que tout chef d'entreprise finit par poser
Vous importez votre catalogue produits, votre FAQ, votre politique de retour. Vous cliquez sur un bouton. Quelques secondes plus tard, le chatbot répond à la question d'un client sur une variante produit spécifique de votre gamme — correctement, complètement, sans rien inventer.
Comment a-t-il fait ?
La réponse honnête : l'IA n'a rien mémorisé. Elle n'a pas appris vos documents par cœur. Ce qui s'est passé est plus intéressant — et le comprendre va changer fondamentalement la façon dont vous construisez, entretenez et diagnostiquez votre assistant IA.
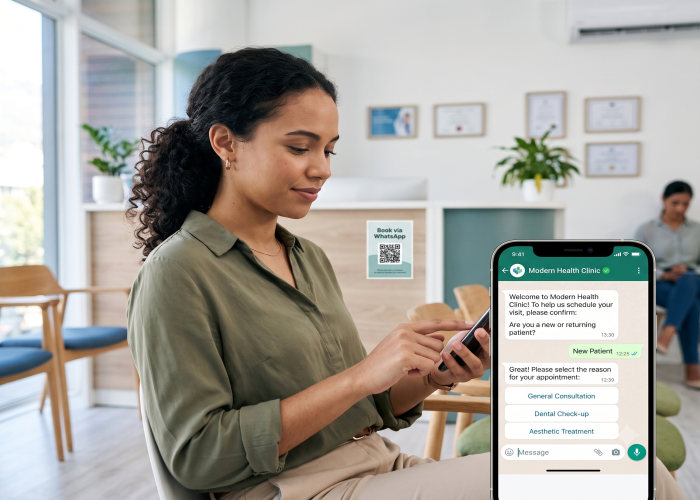
La technologie s'appelle RAG. L'acronyme signifie Retrieval-Augmented Generation — génération augmentée par récupération. C'est désormais l'architecture standard qui propulse pratiquement chaque chatbot IA professionnel capable de répondre réellement aux questions spécifiques à votre entreprise — des bots WhatsApp aux widgets de site web en passant par l'automatisation des DM Instagram.
Pourquoi les modèles IA ne « connaissent » pas votre entreprise d'eux-mêmes
Les grands modèles de langage comme GPT-4o ont été entraînés sur des quantités énormes de texte — livres, sites web, articles, code — et couvrent une étendue extraordinaire de la connaissance humaine. Ils peuvent écrire, raisonner, résumer, traduire et expliquer avec une fluidité remarquable.
Mais ils ont été entraînés sur des données publiques. Ils ne connaissent pas votre catalogue produits. Ils ne connaissent pas vos prix. Ils ne connaissent pas votre politique de retour, vos adresses de filiales, les noms de vos collaborateurs, ni ce que vous avez modifié mardi dernier.
On pourrait théoriquement réentraîner le modèle from scratch sur vos données — mais c'est extraordinairement coûteux, techniquement complexe, et devrait être répété à chaque modification de vos informations. Pas viable pour une entreprise.
L'autre option serait de coller l'intégralité de votre base de connaissances dans chaque conversation : « voici tous nos produits, toutes nos politiques, toutes nos FAQ — réponds maintenant à cette question client. » Cela fonctionne pour les petites bases de connaissances. Mais une entreprise typique peut avoir des centaines de documents, des milliers d'entrées produits et des dizaines de milliers de mots de contenu. Envoyer tout ça à chaque message est lent, coûteux et se heurte rapidement aux limites de ce qu'un modèle peut traiter en une seule fois.
Le RAG résout ce problème élégamment. Au lieu de tout donner à l'IA, il lui donne exactement ce dont elle a besoin — au moment où elle en a besoin.
Ce que le RAG fait concrètement
Retrieval-Augmented Generation combine deux choses qui semblent distinctes mais fonctionnent ensemble en quelques millisecondes :
Retrieval (récupération) — trouver les passages spécifiques de votre base de connaissances les plus pertinents par rapport à la question du client.
Generation (génération) — l'IA utilise les passages récupérés pour composer une réponse naturelle et précise.
Voici la séquence complète, étape par étape :
1. Vos documents sont traités et indexés
Lorsque vous importez du contenu — un PDF, une URL, un document — le système ne le stocke pas comme du texte brut en attente d'être recherché. Il traite le contenu dans un format structuré optimisé pour la recherche sémantique. Cette étape s'effectue une seule fois, lors de l'ajout ou de la mise à jour du contenu.
2. Le client envoie un message
Un client écrit : « Proposez-vous la livraison express à Paris le jour même ? »
3. Le système recherche le contenu pertinent dans votre base de connaissances
Avant que l'IA n'écrive un seul mot, le système effectue une recherche dans votre base de connaissances indexée. Il cherche les passages de votre contenu les plus pertinents par rapport à la question. Ce n'est pas une recherche par mots-clés — c'est une recherche sémantique. Elle comprend que « livraison express » et « livraison le jour même » sont des concepts liés, même si vos documents utilisent des formulations différentes.
4. Le contenu le plus pertinent est récupéré
Le système renvoie deux ou trois passages les plus pertinents de votre base de connaissances — par exemple, une section de votre page de politique de livraison et un paragraphe de votre FAQ sur les zones de livraison. Seulement ceux-là. Pas l'intégralité de votre catalogue.
5. L'IA génère une réponse à partir du contenu récupéré
Le modèle reçoit : la question du client, les passages récupérés, et des instructions sur la façon de répondre. Il utilise cette combinaison pour rédiger une réponse naturelle et précise. Il ne devine pas. Il ne s'appuie pas sur ses connaissances générales. Il travaille à partir de votre contenu spécifique.
6. La réponse est renvoyée au client
L'ensemble du processus — récupération plus génération — prend une fraction de seconde.
L'étape d'indexation : plus importante qu'il n'y paraît
Lorsque votre contenu est traité pour la première fois, il passe par une étape appelée chunking — la division de vos documents en segments plus petits et recherchables. C'est là que réside une grande partie de la différence de qualité entre les plateformes de chatbot IA, et cela vaut la peine d'être compris.
Imaginez que votre document de politique de retour fasse 2 000 mots. Le système ne l'indexe pas comme un seul bloc géant. Il le découpe en morceaux qui se chevauchent — typiquement quelques centaines de mots chacun — chaque morceau capturant un bloc d'information cohérent.
Pourquoi se chevaucher ? Parce que les informations importantes ne s'inscrivent pas toujours proprement à l'intérieur d'une limite de morceau. Une phrase qui commence à la fin d'un morceau peut se terminer au début du suivant. Les morceaux chevauchants — où chaque segment partage une partie de contenu avec ses voisins — garantissent que le contexte n'est pas perdu aux frontières.
Un système de chunking bien conçu utilise également des fenêtres glissantes : les morceaux avancent d'un nombre fixe de mots plutôt que de se couper abruptement à des points fixes. Il en résulte un ensemble de segments chevauchants qui portent chacun suffisamment de contexte environnant pour être significatifs lorsqu'ils sont récupérés de façon isolée.
L'impact pratique : avec un bon chunking, votre chatbot peut répondre à une question sur une clause spécifique de votre politique de retour sans récupérer l'intégralité du document. Avec un chunking médiocre, vous obtenez des réponses tronquées, sans contexte, ou du contenu vaguement pertinent plutôt que le passage précis dont le client avait besoin.
Comment fonctionne la recherche : les vecteurs
L'étape de récupération utilise une technologie appelée embeddings vectoriels — une méthode qui convertit le texte en représentations numériques codant le sens, et non simplement les mots.
L'intuition : dans l'espace vectoriel, la phrase « livraison le lendemain » et la phrase « expédition express » sont proches l'une de l'autre, parce qu'elles signifient des choses similaires. « Politique de retour » et « comment retourner un article » sont proches. « Horaires d'ouverture » et « quand êtes-vous ouverts » sont proches.
C'est fondamentalement différent de la recherche par mots-clés. Une recherche par mots-clés sur « livraison express » raterait un document qui utilise l'expression « envoi le jour même ». Une recherche vectorielle le trouve, parce que le sens est similaire même si les mots diffèrent.
Lorsqu'un client envoie un message, le système le convertit en vecteur et le compare aux vecteurs de tous vos morceaux indexés. Les morceaux avec les scores de similarité les plus élevés — ceux qui sont les plus proches en sens de la question — sont ceux qui sont récupérés.
Recherche hybride : vecteurs denses et creux combinés
Une recherche vectorielle pure est puissante pour la similarité sémantique, mais elle a une faiblesse connue : elle peut parfois manquer les correspondances exactes. Si un client tape un code produit très spécifique, un numéro de modèle ou un nom qui apparaît littéralement dans vos documents, une recherche vectorielle sémantique pourrait ne pas le classer aussi haut qu'une simple correspondance par mots-clés.
C'est pourquoi les systèmes bien conçus utilisent la recherche hybride — en combinant la recherche vectorielle (dense) avec la recherche traditionnelle par mots-clés (creuse), et en fusionnant les résultats via une méthode appelée Reciprocal Rank Fusion, ou RRF.
Le RRF prend les résultats classés des deux méthodes de recherche et les combine en une seule liste, en accordant du crédit aux contenus bien classés dans l'une — ou idéalement les deux. Le résultat est un système de récupération qui gère efficacement à la fois les requêtes « que voulez-vous dire » (sémantique) et « trouvez exactement ceci » (mots-clés), sans avoir à choisir entre les deux.
Pour une entreprise avec un grand catalogue produits plein d'articles, codes et noms spécifiques aux côtés de contenus généraux de politiques et FAQ, la recherche hybride fait une différence notable dans la qualité des réponses.
Ce que cela implique pour votre base de connaissances
Comprendre le RAG change la façon dont vous pensez à la construction et à l'entretien du contenu de votre chatbot.
La couverture est plus importante que le volume. L'IA ne peut répondre qu'à des questions sur ce qui est dans votre base de connaissances. Si les clients posent fréquemment des questions sur les délais de livraison mais que votre contenu importé ne contient pas cette information, le chatbot donnera une réponse vague ou dira qu'il ne sait pas. Ajouter un seul paragraphe clair sur les délais de livraison améliorera immédiatement toutes les questions associées.
La qualité du contenu conditionne la qualité des réponses. Si vos documents importés sont mal structurés — des murs de texte sans organisation claire, une terminologie incohérente, des informations obsolètes mélangées aux informations actuelles — le processus de chunking et de récupération le reflétera. Un contenu propre et bien organisé produit une meilleure récupération, qui produit de meilleures réponses.
Mettre à jour le contenu met à jour le chatbot. Puisque le RAG récupère depuis votre base de connaissances indexée au moment de la requête, mettre à jour votre contenu met à jour les réponses du chatbot. Vous ne réentraînez rien. Importez le nouveau document, et la prochaine conversation utilisera les informations mises à jour.
Les lacunes sont diagnosticables. Si votre chatbot donne des réponses incorrectes ou incomplètes, la cause est presque toujours l'une de ces trois choses : l'information pertinente n'est pas dans votre base de connaissances ; elle y est mais mal structurée ; elle y est mais est déclassée par un contenu moins pertinent. Chacune de ces situations a une solution.
Que se passe-t-il quand la réponse n'est pas dans la base de connaissances
Les systèmes RAG sont conçus pour récupérer et utiliser votre contenu. Lorsqu'une question dépasse ce que couvre votre base de connaissances, le comportement dépend de la façon dont l'agent IA est configuré.
Un chatbot bien configuré reconnaîtra qu'il ne dispose pas de cette information spécifique et proposera de mettre le client en relation avec un agent humain — plutôt que de deviner, d'inventer ou de donner une réponse générique évasive. Cela est contrôlé par le prompt système : les instructions données à l'IA sur la façon de gérer l'incertitude, quand escalader et quel ton maintenir.
Si vous comparez des plateformes sur la profondeur de leur base de connaissances et leur tarification, notre comparatif Ainisa vs Chatbase analyse les deux plateformes avec des chiffres réels.
C'est pourquoi le prompt système n'est pas un détail annexe. C'est la couche qui détermine le comportement de l'IA dans les cas limites — et dans un contexte professionnel, les relations clients se gagnent ou se perdent souvent précisément dans ces cas limites.
Bases de connaissances multilingues
Une question souvent posée : le RAG fonctionne-t-il dans plusieurs langues ?
Oui — avec une nuance importante. Les modèles d'embeddings modernes gèrent bien plusieurs langues. Un client posant une question en français peut retrouver avec succès du contenu rédigé en français, et vice versa. La récupération multilingue — où la question est dans une langue et le contenu pertinent dans une autre — est également possible avec des modèles d'embeddings multilingues, mais fonctionne mieux lorsque la langue du contenu et la langue de requête attendue sont alignées.
Pour les entreprises servant des clients dans plusieurs langues, la recommandation pratique est la suivante : stockez le contenu dans la langue que vos clients utiliseront pour poser des questions à son sujet. Si vos clients en France posent des questions en français, votre FAQ doit être en français. Ne comptez pas sur la récupération multilingue comme substitut à du contenu dans la bonne langue. Cela importe particulièrement pour les entreprises déployées sur des canaux comme WhatsApp et Instagram — découvrez comment les chatbots WhatsApp gèrent le support multilingue en pratique.
RAG vs fine-tuning : une confusion fréquente
Une question qui revient régulièrement : quelle est la différence entre le RAG et le fine-tuning ?
Le fine-tuning consiste à continuer l'entraînement d'un modèle pré-entraîné sur ses propres données. Les poids du modèle — ses paramètres internes — sont modifiés pour intégrer vos informations. Le fine-tuning est coûteux, requiert une expertise technique et produit un résultat statique : la connaissance est « cuite » dans le modèle et ne se met pas à jour automatiquement quand vos données changent.
Le RAG ne modifie pas le modèle du tout. Il lui donne accès à votre contenu au moment de la requête, en récupérant les passages pertinents et en les incluant dans le contexte. Votre base de connaissances se met à jour indépendamment du modèle. Ajouter un nouveau produit ou modifier une politique prend quelques secondes — sans aucune étape de réentraînement.
Pour la grande majorité des cas d'usage professionnels — FAQ produits, politiques, informations de service, tarification, gestion des rendez-vous — le RAG est la bonne architecture. Le fine-tuning est plus approprié pour modifier la façon dont un modèle rédige ou raisonne, pas pour maintenir vos informations métier à jour. Si vous évaluez quelle plateforme de chatbot IA gère bien le RAG, notre tour d'horizon des meilleurs chatbots IA pour les entreprises en 2026 compare les principales options.
Comment Ainisa met en œuvre le RAG
La base de connaissances d'Ainisa est construite sur une architecture RAG hybride utilisant une base de données vectorielle Qdrant. Le contenu est traité avec un chunking à fenêtre glissante avec des segments chevauchants pour préserver le contexte aux frontières des morceaux. La récupération combine la recherche vectorielle dense avec une recherche hybride basée sur le RRF qui mêle vecteurs denses et creux — de sorte que la similarité sémantique et les correspondances exactes sont toutes deux gérées efficacement.
Le système prend en charge plusieurs langues et traite des bases de connaissances multilingues. La base de connaissances de chaque assistant IA est isolée des autres assistants sur la plateforme — votre contenu n'est pas partagé entre comptes.
Ainisa fonctionne également selon le modèle BYOK : les appels IA transitent par votre propre clé API OpenAI ou Anthropic aux tarifs du fournisseur — si vous n'êtes pas familier avec ce fonctionnement, cet article explique le BYOK et pourquoi cela influe sur vos coûts.
Lorsque vous importez un document ou ajoutez une URL, le contenu est automatiquement traité et indexé. Les mises à jour prennent effet immédiatement. Il n'existe aucune étape de réentraînement.
Le principal enseignement
Le RAG n'est pas de la magie — c'est de l'ingénierie. Un chatbot entraîné sur la connaissance de votre entreprise n'est aussi bon que le contenu que vous lui fournissez, la qualité du système de récupération qui l'alimente, et les instructions qui régissent la façon dont l'IA utilise ce qu'elle trouve.
Les entreprises qui tirent le meilleur parti des chatbots IA sont celles qui traitent la base de connaissances comme un document vivant : elles ajoutent du contenu quand des questions restent sans réponse, améliorent la clarté quand les réponses dérivent, et élargissent la couverture au fur et à mesure que leur activité se développe.
L'IA s'occupe du reste.
➤ Essayez Ainisa gratuitement — sans carte bancaire requise ➤ Consultez la documentation Ainisa ➤ Voir les tarifs Ainisa