RAG详解:AI聊天机器人究竟如何从你的业务知识中学习
-
17 3月 2026
-
1995 浏览量

RAG详解:AI聊天机器人究竟如何从你的业务知识中学习
每位企业主迟早都会问的问题
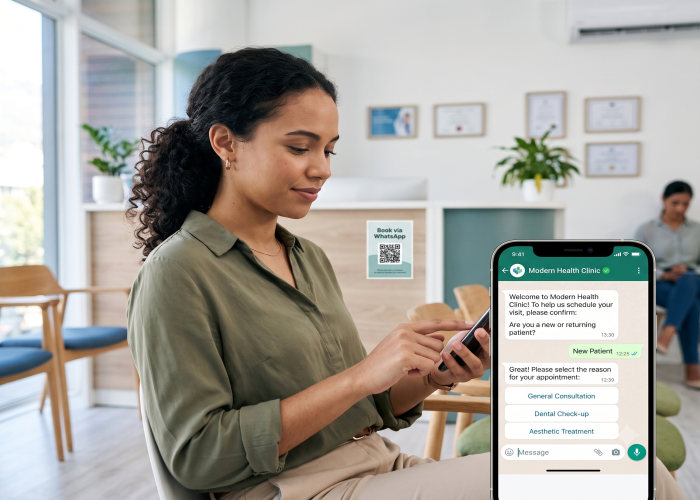
你上传了产品目录、常见问题解答、退款政策。点击一个按钮。几秒钟后,聊天机器人准确回答了客户关于某款具体产品型号的问题——回答正确、完整,没有任何虚构。
它是怎么做到的?
实话实说:AI没有死记硬背任何东西。它没有把你的文档记在脑子里。背后发生的事情更有意思——理解这一点,将从根本上改变你构建、维护和排查AI助手问题的方式。
这项技术叫做RAG,全称Retrieval-Augmented Generation——检索增强生成。它目前已是驱动几乎所有能真正回答企业专属问题的AI聊天机器人的标准架构——从WhatsApp机器人到网站对话插件,再到Instagram私信自动化,莫不如此。
为什么AI模型不会自动"了解"你的企业
GPT-4o这类大型语言模型在海量文本上训练而成——书籍、网站、文章、代码——涵盖了人类知识的惊人广度。它们能够流畅地写作、推理、总结、翻译和解释。
但它们是在公开数据上训练的。它们不知道你的产品目录,不知道你的定价,不知道你的退款政策、分支机构地址、员工姓名,也不知道你上周二改了什么。
理论上,你可以用自己的数据从头重新训练模型——但这极其昂贵、技术复杂,且每次信息更新都需要重来一遍。对企业而言完全不现实。
另一种方案是把整个知识库塞进每次对话:"这是我们所有产品、所有政策、所有FAQ——现在回答这位客户的问题。"对于小型知识库,这行得通。但典型企业可能有数百份文档、数千条产品信息和数万字的内容。每条消息都发送这一切,既慢又贵,而且很快就会撞上模型单次能处理的上下文上限。
RAG优雅地解决了这个问题。它不是把所有东西都给AI,而是在需要的时刻,给它恰好需要的内容。
RAG究竟做了什么
检索增强生成将两件看似独立的事情结合在一起,在毫秒间协同运作:
Retrieval(检索)——找到知识库中与客户问题最相关的具体片段。
Generation(生成)——AI利用检索到的片段,生成自然、准确的回答。
以下是完整流程,逐步拆解:
1. 你的文档被处理并建立索引
当你上传内容——PDF、URL、文档——系统并不是把它作为等待被搜索的原始文本存储起来。它将内容处理成针对语义搜索优化的结构化格式。这一步在内容添加或更新时执行一次。
2. 客户发送消息
客户输入:"你们提供当日达快递吗?"
3. 系统在知识库中搜索相关内容
AI写下任何一个字之前,系统先对你的索引知识库执行搜索,寻找与问题最相关的内容片段。这不是关键词搜索——而是语义搜索。系统能理解"快递"和"当日配送"是相关概念,即便你的文档用了不同的措辞。
4. 最相关的内容被检索出来
系统从知识库中返回两三个最相关的段落——例如配送政策页面的某个章节,以及FAQ中关于配送范围的一段话。仅此而已,而不是你的整个目录。
5. AI基于检索到的内容生成回答
模型收到:客户的问题、检索到的段落、以及如何回答的指令。它用这些组合撰写自然、准确的回答。不是猜测,不是调用通用知识,而是从你的具体内容中工作。
6. 回答返回给客户
整个过程——检索加生成——只需零点几秒。
索引步骤:比看起来更重要
内容首次处理时,会经过一个叫做分块(chunking)的步骤——将文档切分成更小的、可检索的片段。AI聊天机器人平台之间的质量差异,有很大一部分就藏在这里,值得深入理解。
假设你的退款政策文档有2000个字。系统不会把它作为一整块来索引,而是将其切分成互相重叠的片段——通常每段几百个字——每个片段捕捉一个完整的信息块。
为什么要重叠?因为重要信息并不总是整齐地落在单个片段的边界之内。一个句子可能从某个片段末尾开始,在下一个片段开头结束。重叠的片段——每个片段与相邻片段共享部分内容——确保边界处的上下文不会丢失。
设计良好的分块系统还使用滑动窗口:片段以固定数量的词语向前推进,而不是在固定位置生硬截断。结果是一组重叠的片段,每个片段都携带足够的周围上下文,使其在单独检索时仍然有意义。
实际影响:分块做得好,聊天机器人能在不检索整份退款政策文档的情况下,回答关于某一具体条款的问题。分块做得差,你会得到语意截断、缺乏上下文的回答,或者检索到的是模糊相关的内容,而非客户真正需要的那段话。
搜索的工作原理:向量
检索步骤使用一种叫做向量嵌入(vector embeddings)的技术——一种将文本转换为编码含义而非仅仅编码词语的数值表示的方法。
直觉上理解:在向量空间中,"次日达"和"快递配送"彼此相近,因为它们表达相似的意思。"退款政策"和"如何退货"相近。"营业时间"和"你们几点开门"相近。
这与关键词搜索有本质区别。对"快递"的关键词搜索会错过使用"当日配送"措辞的文档。向量搜索能找到它,因为即便词语不同,含义相似。
当客户发送消息时,系统将其转换为向量,与所有已索引片段的向量进行比较。相似度分数最高的片段——在含义上最接近问题的那些——就是被检索出来的片段。
混合检索:稠密向量与稀疏向量协同
纯向量搜索在语义相似性上很强大,但有一个已知的弱点:有时会错过精确匹配。如果客户输入了一个在你文档中一字不差出现的非常具体的产品编号、型号或名称,语义向量搜索的排名可能不如简单的关键词匹配高。
这就是为什么设计良好的系统使用混合检索——将向量(稠密)搜索与传统关键词(稀疏)搜索相结合,并通过一种叫做互惠排名融合(Reciprocal Rank Fusion,RRF)的方法合并结果。
RRF获取两种搜索方法的排名结果,将其合并为一个列表,优先考虑在任一方法——理想情况下在两者——中排名靠前的内容。结果是一个既能处理"你是什么意思"(语义)查询,又能处理"找到这个精确内容"(关键词)查询的检索系统,无需在两者之间做出取舍。
对于拥有大型产品目录——既包含大量具体SKU、编码和名称,又包含通用政策和FAQ内容——的企业,混合检索对回答质量有着显著影响。
这对你的知识库意味着什么
理解RAG,改变了你对构建和维护聊天机器人内容的思考方式。
覆盖面比体量更重要。 AI只能回答知识库中有的内容。如果客户经常询问配送时效,但你上传的内容没有包含这一信息,聊天机器人要么给出模糊回答,要么说不知道。添加一段关于配送时效的清晰说明,会立即改善所有相关问题的回答质量。
内容质量影响回答质量。 如果上传的文档结构混乱——没有清晰组织的大段文字、前后矛盾的术语、过时信息与当前信息混杂——分块和检索过程都会反映这一点。内容干净、组织良好,才能产生更好的检索,进而产生更好的回答。
更新内容即更新聊天机器人。 由于RAG在查询时从你的索引知识库中检索,更新内容就直接更新了聊天机器人的回答。无需重新训练任何东西。上传新文档,下一次对话就会使用更新后的信息。
知识空白可以诊断。 如果聊天机器人给出错误或不完整的回答,原因几乎总是以下三者之一:相关信息不在知识库中;信息在但结构不佳;信息在但被不那么相关的内容排挤。每一个问题都有对应的解决方法。
当答案不在知识库中时会发生什么
RAG系统的设计目的是检索并使用你的内容。当一个问题超出了你的知识库覆盖范围时,行为取决于AI智能体的配置方式。
配置良好的聊天机器人会坦承没有该具体信息,并主动提出将客户转接给人工客服——而不是猜测、杜撰或给出空洞的通用回答。这由系统提示词(system prompt)控制:告诉AI如何处理不确定情况、何时上报人工、保持什么语气的指令。
如果你正在对比各平台的知识库深度和定价,我们的Ainisa vs Chatbase对比分析提供了两个平台的详细数据比较。
这就是为什么系统提示词不是可有可无的附加项。它是决定AI在边缘情况下如何表现的关键层——而在商业场景中,客户关系的得失往往恰恰发生在这些边缘情况中。
多语言知识库
一个常见问题:RAG支持多种语言吗?
支持——但有一个重要的注意点。现代嵌入模型能够很好地处理多种语言。用中文提问的客户可以成功检索到中文编写的内容,反之亦然。使用多语言嵌入模型,跨语言检索——问题是一种语言,相关内容是另一种语言——也是可行的,但在内容语言与预期查询语言一致时效果最佳。
对于服务多语言客户的企业,实际建议是:用客户会用来提问的语言存储内容。如果你的中文客户用中文提问,你的FAQ就应该是中文的。不要把跨语言检索当成拥有正确语言内容的替代品。这一点对于通过WhatsApp和Instagram等渠道运营的企业尤为关键——了解WhatsApp聊天机器人如何在实践中处理多语言支持。
RAG与微调(Fine-tuning):一个常见的混淆
一个经常被提及的问题:RAG和fine-tuning有什么区别?
**Fine-tuning(微调)**是指在自己的数据上继续训练预训练模型。模型的权重——其内部参数——被修改以纳入你的信息。Fine-tuning成本高昂,需要技术专业知识,产生的是静态结果:知识被"烘焙"进模型中,数据发生变化时不会自动更新。
RAG完全不改变模型。它在查询时通过检索相关段落并将其纳入上下文,向模型提供对你内容的访问。你的知识库独立于模型进行更新。添加一款新产品或修改一条政策只需几秒钟——不存在重新训练这个步骤。
对于绝大多数商业用例——产品FAQ、政策、服务信息、定价、预约管理——RAG是正确的架构。Fine-tuning更适合改变模型的写作方式或推理方式,而不是让业务信息保持最新。如果你在评估哪个AI聊天机器人平台对RAG的实现更好,我们的2026年企业最佳AI聊天机器人评测对主要选项进行了详细比较。
Ainisa如何实现RAG
Ainisa的知识库基于使用Qdrant向量数据库的混合RAG架构构建。内容使用带重叠片段的滑动窗口分块处理,以保留片段边界处的上下文。检索将稠密向量搜索与基于RRF的混合检索相结合,融合稠密和稀疏向量——从而有效处理语义相似性和精确匹配两类查询。
系统支持多种语言,能够处理混合语言的知识库。每个AI助手的知识库与平台上的其他助手相互隔离——你的内容不会在账户之间共享。
Ainisa还采用BYOK模式运营:AI调用通过你自己的OpenAI或Anthropic API密钥以提供商费率执行——如果你还不熟悉这一机制的工作原理,这篇文章解释了什么是BYOK以及它为何影响你的成本。
上传文档或添加URL时,内容会自动处理并建立索引。更新立即生效,不存在重新训练的步骤。
实际结论
RAG不是魔法——而是工程。基于你业务知识训练的聊天机器人,其好坏取决于你提供的内容质量、底层检索系统的设计水准,以及规范AI如何运用所检索内容的指令。
从AI聊天机器人中获益最多的企业,是那些将知识库视为活文档来对待的企业:当问题得不到回答时补充内容,当回答出现偏差时提升清晰度,随着业务增长不断扩大覆盖范围。
剩下的,交给AI来完成。