RAG Açıklaması: AI Chatbotlar İşletme Bilginizi Aslında Nasıl Öğrenir
-
17 Mar 2026
-
2006 Görüntülenme

RAG Açıklaması: AI Chatbotlar İşletme Bilginizi Aslında Nasıl Öğrenir
Her İşletme Sahibinin Eninde Sonunda Sorduğu Soru
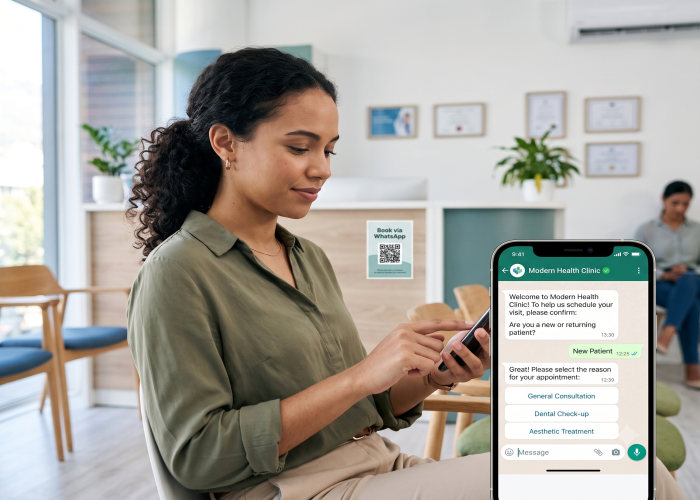
Ürün kataloğunuzu, SSS'nizi, iade politikanızı yüklüyorsunuz. Bir düğmeye tıklıyorsunuz. Birkaç saniye sonra chatbot, stokladığınız belirli bir ürün varyantı hakkındaki müşteri sorusunu — doğru, eksiksiz ve hiçbir şey uydurmadan — yanıtlıyor.
Bunu nasıl başardı?
Dürüst yanıt şu: yapay zeka hiçbir şeyi ezberlemedi. Belgelerinizi aklında tutmadı. Gerçekte olan şey daha ilginç — ve bunu anlamak, AI asistanınızı nasıl kurduğunuzu, bakımını nasıl yaptığınızı ve sorunlarını nasıl giderdiğinizi kökten değiştirecek.
Bu teknolojinin adı RAG. Açılımı: Retrieval-Augmented Generation — erişimle zenginleştirilmiş üretim. Bu, artık neredeyse her iş chatbotunun — WhatsApp botlarından web sitesi widget'larına ve Instagram DM otomasyonuna kadar — gerçekten işletmenize özgü soruları yanıtlayabilmesini sağlayan standart mimaridir.
AI Modeller Neden İşletmenizi Kendiliğinden "Bilmez"
GPT-4o gibi büyük dil modelleri, kitaplar, web siteleri, makaleler, kod gibi muazzam miktarda metin üzerinde eğitilmiştir ve insan bilgisinin olağanüstü geniş bir yelpazesini kapsar. Etkileyici bir akıcılıkla yazabilir, akıl yürütebilir, özetleyebilir, çevirebilir ve açıklayabilirler.
Ancak herkese açık veriler üzerinde eğitildiler. Ürün kataloğunuzu bilmiyorlar. Fiyatlarınızı bilmiyorlar. İade politikanızı, şube adreslerinizi, çalışan adlarınızı ve geçen Salı neyi değiştirdiğinizi bilmiyorlar.
Teorik olarak modeli sıfırdan kendi verilerinizle yeniden eğitebilirsiniz — ancak bu son derece pahalıdır, teknik uzmanlık gerektirir ve bilgileriniz her değiştiğinde tekrarlanması gerekir. Bir işletme için bu sürdürülebilir değildir.
Diğer seçenek, her konuşmaya tüm bilgi tabanınızı yapıştırmak olurdu: "işte tüm ürünlerimiz, tüm politikalarımız, tüm SSS'lerimiz — şimdi bu müşterinin sorusunu yanıtla." Bu, küçük bilgi tabanları için işe yarar. Ancak tipik bir işletmenin yüzlerce belgesi, binlerce ürün girişi ve on binlerce kelimelik içeriği olabilir. Her mesajla bunların hepsini göndermek yavaş, pahalı ve modelin aynı anda işleyebileceği hacmin sınırlarına hızla çarpar.
RAG bunu zarif bir şekilde çözer. Yapay zekaya her şeyi vermek yerine, tam olarak ihtiyacı olanı — ihtiyaç duyduğu anda verir.
RAG Aslında Ne Yapar
Retrieval-Augmented Generation, ayrı gibi görünen ancak milisaniyeler içinde birlikte çalışan iki şeyi bir araya getirir:
Retrieval (erişim) — müşterinin sorusuyla en ilgili bilgi tabanı parçalarını bulmak.
Generation (üretim) — yapay zekanın bulunan parçaları kullanarak doğal, doğru bir yanıt oluşturması.
İşte adım adım tam sıra:
1. Belgeleriniz işlenir ve indekslenir
İçerik yüklediğinizde — PDF, URL, belge — sistem bunu arama bekleyen "ham" metin olarak saklamaz. İçeriği anlamsal arama için optimize edilmiş yapılandırılmış bir biçime işler. Bu adım, içerik eklendiğinde veya güncellendiğinde bir kez gerçekleşir.
2. Müşteri bir mesaj gönderir
Müşteri yazar: "İstanbul'a aynı gün teslimat yapıyor musunuz?"
3. Sistem bilgi tabanınızda ilgili içeriği arar
Yapay zeka tek bir kelime yazmadan önce, sistem indekslenmiş bilgi tabanınızda bir arama yapar. Soruyla en ilgili içerik parçalarını arar. Bu bir anahtar kelime araması değil — anlamsal bir aramadır. Sistem, belgeleriniz farklı ifadeler kullansa bile "ekspres teslimat" ve "aynı gün kargo"nun ilişkili kavramlar olduğunu anlar.
4. En ilgili içerik geri alınır
Sistem, bilgi tabanınızdan en ilgili iki veya üç pasajı geri getirir — örneğin kargo politikası sayfanızdan bir bölüm ve teslimat bölgeleri hakkındaki SSS'den bir paragraf. Yalnızca bunları. Tüm kataloğunuzu değil.
5. Yapay zeka bulunan içeriği kullanarak bir yanıt üretir
Model şunları alır: müşterinin sorusunu, bulunan pasajları ve nasıl yanıt vereceğine dair talimatları. Bu kombinasyonu kullanarak doğal, doğru bir yanıt yazar. Tahmin etmiyor. Genel bilgisine başvurmuyor. Sizin özel içeriğinizden çalışıyor.
6. Yanıt müşteriye geri döndürülür
Tüm süreç — erişim artı üretim — saniyenin küçük bir bölümünü alır.
İndeksleme Adımı: Göründüğünden Daha Önemli
İçeriğiniz ilk işlendiğinde, chunking adı verilen bir aşamadan geçer — belgelerinizi daha küçük, aranabilir segmentlere bölmek. AI chatbot platformları arasındaki kalite farkının büyük bir kısmı tam da burada yatar ve bunu anlamak faydalıdır.
İade politikası belgenizin 2.000 kelime olduğunu hayal edin. Sistem bunu tek bir büyük blok olarak indekslemez. Örtüşen parçalara böler — genellikle birkaç yüz kelimeden oluşan — ve her parça tutarlı bir bilgi bloğu yakalar.
Neden örtüşme? Çünkü önemli bilgiler her zaman tek bir parça sınırına sığmaz. Bir parçanın sonunda başlayan bir cümle, bir sonraki parçanın başında tamamlanabilir. Örtüşen parçalar — her segmentin komşularıyla bazı içerikleri paylaşması — sınırlarda bağlamın kaybolmamasını sağlar.
İyi tasarlanmış bir chunking sistemi ayrıca kayan pencereler kullanır: parçalar sabit noktalarda sert bir şekilde kesilmek yerine sabit sayıda kelimeyle ilerler. Sonuç, her biri yalıtılmış olarak alındığında anlamlı olmak için yeterli çevre bağlamı taşıyan örtüşen segmentler kümesidir.
Pratik etki: iyi chunking ile chatbotunuz tüm belgeyi almadan iade politikanızdaki belirli bir madde hakkındaki soruyu yanıtlayabilir. Zayıf chunking ile yarım kalmış, bağlamdan kopuk yanıtlar ya da tam olarak gereken pasaj yerine belirsiz şekilde ilgili içerik alırsınız.
Arama Nasıl Çalışır: Vektörler
Erişim adımı, metni yalnızca kelimeleri değil anlamı kodlayan sayısal temsillere dönüştürme yöntemi olan vektör gömme (embedding) teknolojisini kullanır.
Sezgi şudur: vektör uzayında "ertesi gün teslimat" ifadesi ile "ekspres kargo" ifadesi birbirine yakındır, çünkü benzer şeyler ifade ederler. "İade politikası" ile "bir ürünü nasıl iade ederim" yakındır. "Çalışma saatleri" ile "ne zaman açıksınız" yakındır.
Bu, anahtar kelime aramasından kökten farklıdır. "Ekspres teslimat" için yapılan bir anahtar kelime araması, "aynı gün sevkiyat" ifadesini kullanan bir belgeyi atlar. Vektör araması onu bulur, çünkü kelimeler farklı olsa bile anlam benzerdir.
Müşteri bir mesaj gönderdiğinde, sistem bunu bir vektöre dönüştürür ve tüm indekslenmiş parçaların vektörleriyle karşılaştırır. En yüksek benzerlik puanına sahip parçalar — soruya anlamca en yakın olanlar — alınan parçalardır.
Hibrit Arama: Yoğun ve Seyrek Birlikte
Saf vektör araması anlamsal benzerlik için güçlüdür, ancak bilinen bir zayıflığı vardır: bazen tam eşleşmeleri kaçırabilir. Bir müşteri belgelerinizde kelimesi kelimesine bulunan çok spesifik bir ürün kodu, model numarası veya isim yazarsa, anlamsal vektör araması bunu basit bir anahtar kelime eşleşmesinin yapacağından daha düşük sıralayabilir.
Bu nedenle iyi tasarlanmış sistemler hibrit arama kullanır — vektör (yoğun) aramayı geleneksel anahtar kelime (seyrek) aramayla birleştirir ve sonuçları Reciprocal Rank Fusion (RRF) adı verilen bir yöntemle birleştirir.
RRF, her iki arama yönteminden sıralı sonuçları alır ve bunları tek bir listeye birleştirir; herhangi birinde — ideal olarak her ikisinde — iyi sıralanan içeriklere kredi verir. Sonuç, aralarında seçim yapmak zorunda kalmadan hem "ne demek istiyorsunuz" (anlamsal) hem de "tam olarak bunu bul" (anahtar kelime) sorgularını etkili bir şekilde işleyen bir arama sistemidir.
Genel politika ve SSS içeriğiyle birlikte belirli SKU'lar, kodlar ve isimlerle dolu büyük bir ürün kataloğuna sahip işletmeler için hibrit arama, yanıt kalitesinde anlamlı bir fark yaratır.
Bu Bilgi Tabanınız İçin Ne Anlama Gelir
RAG'ı anlamak, chatbotunuzun içeriğini oluşturma ve sürdürme konusundaki düşüncenizi değiştirir.
Kapsam hacimden daha önemlidir. Yapay zeka yalnızca bilgi tabanınızdaki şeyler hakkında yanıt verebilir. Müşteriler sıklıkla teslimat süreleri hakkında soruyorsa ancak yüklenen içeriğiniz bu bilgiyi içermiyorsa, chatbot belirsiz bir yanıt verecek ya da bilmediğini söyleyecektir. Teslimat süreleri hakkında tek bir net paragraf eklemek, ilgili her soruyu hemen iyileştirecektir.
İçerik kalitesi yanıt kalitesini etkiler. Yüklenen belgeler kötü yapılandırılmışsa — net bir organizasyon olmadan metin duvarları, tutarsız terminoloji, güncel bilgiyle karışık güncelliğini yitirmiş bilgi — chunking ve erişim süreci bunu yansıtacaktır. Temiz, iyi organize edilmiş içerik daha iyi erişim sağlar ve bu da daha iyi yanıtlar üretir.
İçeriği güncellemek chatbotu günceller. RAG, bilgi tabanınızdan sorgu anında aldığı için içeriğinizi güncellemek chatbotun yanıtlarını günceller. Hiçbir şeyi yeniden eğitmezsiniz. Yeni belgeyi yükleyin ve bir sonraki konuşma güncellenmiş bilgiyi kullanır.
Boşluklar teşhis edilebilir. Chatbotunuz yanlış veya eksik yanıtlar veriyorsa, neden neredeyse her zaman üç şeyden biridir: ilgili bilgi bilgi tabanınızda değildir; oradadır ancak kötü yapılandırılmıştır; oradadır ancak daha az ilgili içerik tarafından sıralamadan düşürülmektedir. Her birinin bir çözümü vardır.
Yanıt Bilgi Tabanında Olmadığında Ne Olur
RAG sistemleri içeriğinizi almak ve kullanmak için tasarlanmıştır. Bir soru bilgi tabanınızın kapsadığının dışına çıktığında, davranış AI ajanının nasıl yapılandırıldığına bağlıdır.
İyi yapılandırılmış bir chatbot, o spesifik bilgiye sahip olmadığını kabul eder ve müşteriyi bir insan temsilcisine bağlamayı teklif eder — tahmin etmek, uydurmak ya da genel bir yanıt vermek yerine. Bu, sistem promptu tarafından kontrol edilir: belirsizliği nasıl ele alacağına, ne zaman yönlendireceğine ve hangi tonu koruyacağına dair yapay zekaya verilen talimatlar.
Bilgi tabanı derinliği ve fiyatlandırma açısından platformları karşılaştırıyorsanız, Ainisa vs Chatbase karşılaştırmamız her iki platformu gerçek rakamlarla ele alıyor.
Bu nedenle sistem promptu bir ayrıntı değildir. Yapay zekanın sınır durumlarındaki davranışını belirleyen katmandır — ve iş bağlamında, sınır durumlarında müşteri ilişkileri genellikle kazanılır ya da kaybedilir.
Çok Dilli Bilgi Tabanları
Sıkça sorulan bir soru: RAG farklı dillerde çalışıyor mu?
Evet — önemli bir nüansla. Modern gömme modelleri birden fazla dili iyi işler. Türkçe soru soran bir müşteri, Türkçe yazılmış içeriği başarıyla bulabilir ve bunun tersi de geçerlidir. Çok dilli gömme modelleriyle çapraz dil erişimi — sorunun bir dilde, ilgili içeriğin başka bir dilde olduğu durum — da mümkündür; ancak içerik ve beklenen sorgu dili hizalandığında en iyi şekilde çalışır.
Birden fazla dilde müşterilere hizmet veren işletmeler için pratik öneri şudur: içeriği müşterilerinizin onun hakkında soru soracağı dilde saklayın. Türkiye'deki müşterileriniz Türkçe soracaksa, SSS'niz Türkçe olmalıdır. Doğru dildeki içeriğin yerini tutacak şekilde çapraz dil erişimine güvenmeyin. Bu özellikle WhatsApp ve Instagram gibi kanallar üzerinden çalışan işletmeler için önemlidir — WhatsApp chatbotlarının çok dilli desteği pratikte nasıl ele aldığına bakın.
RAG ve İnce Ayar (Fine-Tuning): Yaygın Bir Karışıklık
Düzenli olarak gündeme gelen bir soru: RAG ile fine-tuning arasındaki fark nedir?
Fine-tuning, önceden eğitilmiş bir modeli kendi verileriniz üzerinde eğitmeye devam etmek demektir. Modelin ağırlıkları — iç parametreleri — bilgilerinizi içerecek şekilde değiştirilir. Fine-tuning pahalıdır, teknik uzmanlık gerektirir ve statik bir sonuç üretir: bilgi modele "pişirilir" ve verileriniz değiştiğinde otomatik olarak güncellenmez.
RAG modeli hiç değiştirmez. İlgili pasajları alıp bağlama dahil ederek sorgu anında modele içeriğinize erişim sağlar. Bilgi tabanınız modelden bağımsız olarak güncellenir. Yeni bir ürün eklemek veya bir politikayı değiştirmek saniyeler alır — herhangi bir yeniden eğitim adımı olmadan.
İş kullanım durumlarının büyük çoğunluğu için — ürün SSS'leri, politikalar, hizmet bilgileri, fiyatlandırma, randevu yönetimi — RAG doğru mimaridir. Fine-tuning, bir modelin nasıl yazdığını veya akıl yürüttüğünü değiştirmek için daha uygundur; iş bilgilerinizi güncel tutmak için değil. Hangi AI chatbot platformasının RAG'ı iyi işlediğini değerlendiriyorsanız, 2026'daki en iyi iş chatbotları incelememiz önde gelen seçenekleri karşılaştırıyor.
Ainisa RAG'ı Nasıl Uygular
Ainisa'nın bilgi tabanı, Qdrant vektör veritabanı kullanan hibrit bir RAG mimarisi üzerine kurulmuştur. İçerik, parça sınırlarında bağlamı korumak için örtüşen segmentlerle kayan pencere chunking kullanılarak işlenir. Erişim, yoğun ve seyrek vektörleri birleştiren RRF tabanlı hibrit aramayla yoğun vektör aramasını birleştirir — böylece hem anlamsal benzerlik hem de tam eşleşmeler etkili bir şekilde işlenir.
Sistem birden fazla dili destekler ve karma dilli bilgi tabanlarını işler. Her AI asistanının bilgi tabanı, platformdaki diğer asistanlardan izole edilmiştir — içeriğiniz diğer hesaplarla paylaşılmaz.
Ainisa ayrıca BYOK modeliyle çalışır: AI çağrıları, sağlayıcı tarifeleriyle kendi OpenAI veya Anthropic API anahtarınız üzerinden yapılır — bunun nasıl çalıştığına aşina değilseniz, bu yazı BYOK'u ve maliyetlerinizi neden etkilediğini açıklıyor.
Bir belge yüklediğinizde veya URL eklediğinizde, içerik otomatik olarak işlenir ve indekslenir. Güncellemeler hemen geçerli olur. Yeniden eğitim adımı yoktur.
Pratik Çıkarım
RAG sihir değil — mühendisliktir. İşletme bilginiz üzerinde eğitilmiş bir chatbot, yalnızca ona verdiğiniz içerik, altındaki erişim sisteminin kalitesi ve yapay zekanın bulduklarını nasıl kullanacağını yöneten talimatlar kadar iyidir.
AI chatbotlardan en fazla yararlanan işletmeler, bilgi tabanına yaşayan bir belge gibi davrananlar: sorular yanıtsız kaldığında içerik ekliyor, yanıtlar saptığında netliği iyileştiriyor ve işletme büyüdükçe kapsamı genişletiyorlar.
Yapay zeka gerisini halleder.
➤ Ainisa'yı Ücretsiz Deneyin — Kart Gerekmez ➤ Ainisa Belgelerini Okuyun ➤ Ainisa Fiyatlandırması