RAG простыми словами: как AI-чатботы на самом деле учатся на знаниях вашего бизнеса
-
17 мар 2026
-
1999 Просмотры

RAG простыми словами: как AI-чатботы на самом деле учатся на знаниях вашего бизнеса
Вопрос, который рано или поздно задаёт каждый
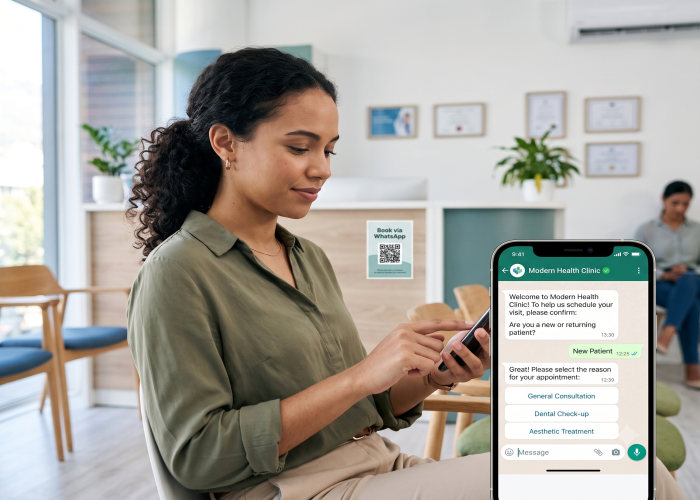
Вы загружаете каталог товаров, FAQ, политику возврата. Нажимаете кнопку. Через несколько секунд чатбот точно отвечает клиенту на вопрос о конкретной позиции из вашего ассортимента — без ошибок и выдумок.
Как ему это удалось?
Честный ответ: ИИ ничего не запоминал. Он не заучил ваши документы наизусть. То, что произошло, устроено интереснее — и понимание этого изменит то, как вы строите, обслуживаете и диагностируете своего AI-ассистента.
Технология называется RAG. Расшифровывается как Retrieval-Augmented Generation — генерация с дополнением поиском. Это стандартная архитектура, на которой сегодня работает практически каждый бизнес-чатбот, способный реально отвечать на вопросы именно о вашем бизнесе — от WhatsApp-ботов до виджетов на сайте и автоматизации в Instagram.
Почему ИИ-модели не «знают» ваш бизнес сами по себе
Большие языковые модели вроде GPT-4o обучены на огромных массивах текста — книгах, сайтах, статьях, коде — и охватывают широчайший пласт человеческих знаний. Они умеют писать, рассуждать, резюмировать, переводить и объяснять с впечатляющим качеством.
Но их обучали на публичных данных. Они не знают ваш каталог товаров. Не знают ваши цены. Не знают вашу политику возврата, адреса филиалов, имена сотрудников и то, что вы изменили в прошлый вторник.
Теоретически можно дообучить модель с нуля на ваших данных — но это колоссально дорого, требует технической экспертизы и должно повторяться каждый раз при изменении информации. Для бизнеса это нежизнеспособно.
Другой вариант — вставлять всю вашу базу знаний в каждый диалог: «вот все наши товары, все правила, все FAQ — теперь ответь на вопрос клиента». Для небольшой базы это работает. Но у типичного бизнеса могут быть сотни документов, тысячи товарных позиций и десятки тысяч слов контента. Отправлять всё это с каждым сообщением — медленно, дорого и быстро упирается в ограничения на объём контекста.
RAG решает эту задачу элегантно. Вместо того чтобы давать ИИ всё, он даёт ровно то, что нужно — в нужный момент.
Что RAG делает на практике
Retrieval-Augmented Generation объединяет две вещи, которые звучат как отдельные процессы, но работают вместе за миллисекунды:
Retrieval (поиск) — нахождение конкретных фрагментов вашей базы знаний, наиболее релевантных вопросу клиента.
Generation (генерация) — использование ИИ для составления естественного, точного ответа на основе найденных фрагментов.
Вот полная последовательность, шаг за шагом:
1. Ваши документы обрабатываются и индексируются
Когда вы загружаете контент — PDF, URL, документ — система не хранит его как «сырой» текст в ожидании поиска. Контент обрабатывается в структурированный формат, оптимизированный для семантического поиска. Этот шаг происходит один раз при добавлении или обновлении контента.
2. Клиент отправляет сообщение
Клиент пишет: «Вы доставляете в Баку в день заказа?»
3. Система ищет релевантный контент в базе знаний
Прежде чем ИИ напишет хотя бы слово, система выполняет поиск по вашей индексированной базе знаний. Она ищет фрагменты контента, наиболее подходящие к заданному вопросу. Это не поиск по ключевым словам — это семантический поиск. Система понимает, что «экспресс-доставка» и «доставка в день заказа» — родственные понятия, даже если в ваших документах используются разные формулировки.
4. Наиболее релевантный контент извлекается
Система возвращает два-три наиболее подходящих отрывка из вашей базы знаний — например, раздел из страницы условий доставки и абзац из FAQ о зонах доставки. Только их. Не весь ваш каталог.
5. ИИ генерирует ответ на основе найденного контента
Модель получает: вопрос клиента, найденные отрывки и инструкции по стилю ответа. На основе этого она составляет естественный, точный ответ. Никаких догадок. Никакого использования общих знаний. Только ваш конкретный контент.
6. Ответ возвращается клиенту
Весь процесс — поиск плюс генерация — занимает долю секунды.
Этап индексации: почему он важнее, чем кажется
При первоначальной обработке ваш контент проходит через этап, называемый чанкингом (chunking) — разбивкой документов на более мелкие, доступные для поиска сегменты. Именно здесь кроется значительная часть разницы в качестве между AI-чатбот платформами, и это стоит понимать.
Представьте, что ваш документ с политикой возврата занимает 2 000 слов. Система не индексирует его как один большой блок. Она разбивает его на перекрывающиеся фрагменты — обычно по несколько сотен слов — при этом каждый фрагмент охватывает цельный смысловой блок.
Зачем перекрытие? Потому что важная информация не всегда укладывается аккуратно в границы одного фрагмента. Предложение, начатое в конце одного чанка, может завершаться в начале следующего. Перекрывающиеся фрагменты — где каждый сегмент разделяет часть контента с соседями — гарантируют, что контекст не теряется на границах.
Хорошо спроектированная система чанкинга также использует скользящие окна: фрагменты сдвигаются на фиксированное количество слов, а не обрываются жёстко в фиксированных точках. В итоге получается набор перекрывающихся сегментов, каждый из которых несёт достаточно контекста, чтобы быть осмысленным при извлечении в отрыве от остального.
Практический эффект: при качественном чанкинге чатбот может ответить на вопрос о конкретном пункте политики возврата, не извлекая весь документ целиком. При плохом чанкинге вы получаете ответы, оборванные на полуслове, лишённые контекста, или извлекаются смежные, но не точные фрагменты вместо нужного.
Как устроен поиск: векторы
На этапе поиска используется технология векторных эмбеддингов — метод преобразования текста в числовые представления, кодирующие смысл, а не просто слова.
Интуиция такая: в векторном пространстве фраза «доставка на следующий день» и фраза «экспресс-доставка» находятся близко друг к другу, потому что означают схожее. «Политика возврата» и «как вернуть товар» — близко. «Часы работы» и «когда вы открыты» — близко.
Это принципиально отличается от поиска по ключевым словам. Ключевой поиск по «экспресс-доставке» пропустит документ, в котором используется фраза «доставка в день заказа». Векторный поиск найдёт его, потому что смысл схож, даже если слова различаются.
Когда клиент отправляет сообщение, система преобразует его в вектор и сравнивает со всеми векторами индексированных фрагментов. Фрагменты с наибольшим сходством — те, что по смыслу ближе всего к вопросу — и извлекаются.
Гибридный поиск: плотные и разреженные векторы вместе
Чистый векторный поиск мощен для семантического сходства, но у него есть известная слабость: он иногда упускает точные совпадения. Если клиент вводит очень конкретный артикул, номер модели или название, присутствующее в ваших документах дословно, семантический векторный поиск может ранжировать его ниже, чем простое ключевое совпадение.
Именно поэтому хорошо спроектированные системы используют гибридный поиск — сочетание векторного (плотного) поиска с традиционным ключевым (разреженным) поиском, с объединением результатов методом Reciprocal Rank Fusion (RRF).
RRF берёт ранжированные результаты обоих методов поиска и объединяет их в единый список, отдавая предпочтение контенту, который хорошо ранжируется в любом из них — а в идеале в обоих. В итоге система поиска эффективно обрабатывает как «что вы имеете в виду» (семантика), так и «найди именно это» (ключевые слова), не выбирая между ними.
Для бизнеса с большим каталогом, полным конкретных артикулов, кодов и названий, в сочетании с общим контентом по правилам и FAQ, гибридный поиск ощутимо влияет на качество ответов.
Что это означает для вашей базы знаний
Понимание RAG меняет подход к созданию и ведению контента для чатбота.
Полнота важнее объёма. ИИ может отвечать только на то, что есть в вашей базе знаний. Если клиенты часто спрашивают о сроках доставки, а загруженный контент этой информации не содержит, чатбот даст размытый ответ или скажет, что не знает. Один чёткий абзац о сроках доставки немедленно улучшит все связанные ответы.
Качество контента влияет на качество ответов. Если загруженные документы плохо структурированы — стены текста без чёткой организации, непоследовательная терминология, устаревшая информация вперемешку с актуальной — чанкинг и поиск отразят это. Чистый, хорошо организованный контент даёт лучший поиск, который даёт лучшие ответы.
Обновление контента обновляет чатбота. Поскольку RAG извлекает данные из вашей индексированной базы в момент запроса, обновление контента обновляет и ответы чатбота. Ничего переобучать не нужно. Загрузите новый документ — и следующий разговор уже использует обновлённую информацию.
Пробелы поддаются диагностике. Если чатбот даёт неправильные или неполные ответы, причина почти всегда одна из трёх: нужной информации нет в базе знаний; она есть, но плохо структурирована; она есть, но вытесняется менее релевантным контентом. У каждой из них есть решение.
Что происходит, когда ответа нет в базе знаний
RAG-системы созданы для извлечения и использования вашего контента. Когда вопрос выходит за рамки базы знаний, поведение зависит от того, как настроен AI-агент.
Хорошо настроенный чатбот признает, что конкретной информации у него нет, и предложит соединить клиента с оператором — вместо того чтобы угадывать, выдумывать или давать общий уклончивый ответ. Это управляется системным промптом: инструкциями для ИИ о том, как вести себя в нестандартных ситуациях, когда эскалировать и какой тон поддерживать.
Если вы сравниваете платформы с точки зрения глубины работы с базой знаний и ценообразования, наш сравнительный обзор Ainisa vs Chatbase разбирает обе платформы с реальными цифрами.
Именно поэтому системный промпт — не мелкая деталь. Это слой, определяющий поведение ИИ на граничных случаях — а в бизнес-контексте именно на граничных случаях зачастую выигрываются или теряются клиентские отношения.
Многоязычные базы знаний
Частый вопрос: работает ли RAG на разных языках?
Да — с важной оговоркой. Современные модели эмбеддингов хорошо справляются с несколькими языками. Клиент, задающий вопрос по-русски, успешно найдёт контент, написанный по-русски, и наоборот. Кросс-языковой поиск — когда вопрос на одном языке, а релевантный контент на другом — тоже возможен с многоязычными моделями, хотя работает лучше всего, когда язык контента совпадает с языком ожидаемых запросов.
Для бизнеса, обслуживающего клиентов на разных языках, практическая рекомендация такова: храните контент на том языке, на котором клиенты будут задавать о нём вопросы. Если ваши клиенты в России пишут по-русски — FAQ должен быть на русском. Не полагайтесь на кросс-языковой поиск как замену контенту на нужном языке. Это особенно важно для бизнесов, работающих через WhatsApp и Instagram — как WhatsApp-чатботы справляются с многоязычной поддержкой на практике.
RAG против тонкой настройки: распространённая путаница
Вопрос, который возникает регулярно: чем RAG отличается от fine-tuning (тонкой настройки)?
Fine-tuning означает продолжение обучения предобученной модели на ваших собственных данных. Веса модели — её внутренние параметры — изменяются так, чтобы включить вашу информацию. Fine-tuning дорог, требует технической экспертизы и даёт статичный результат: знания запекаются в модель и не обновляются автоматически при изменении данных.
RAG не изменяет модель вообще. Он даёт модели доступ к вашему контенту в момент запроса, извлекая релевантные фрагменты и включая их в контекст. Ваша база знаний обновляется независимо от модели. Добавить новый товар или изменить правило занимает секунды — без какого-либо переобучения.
Для подавляющего большинства бизнес-задач — FAQ по продуктам, правила, информация об услугах, цены, запись на приём — RAG является правильной архитектурой. Fine-tuning больше подходит для изменения того, как модель пишет или рассуждает, а не для актуализации бизнес-информации. Если вы оцениваете, какая AI-чатбот платформа лучше справляется с RAG, наш обзор лучших AI-чатботов для бизнеса в 2026 году сравнивает ведущие варианты.
Как RAG реализован в Ainisa
База знаний Ainisa построена на гибридной RAG-архитектуре с использованием векторной базы данных Qdrant. Контент обрабатывается с помощью чанкинга на основе скользящего окна с перекрывающимися сегментами для сохранения контекста на границах фрагментов. Поиск объединяет плотный векторный поиск с разреженным ключевым поиском, объединяемым методом Reciprocal Rank Fusion — так эффективно обрабатываются как семантическое сходство, так и точные совпадения.
Система поддерживает несколько языков и работает со смешанными по языку базами знаний. База знаний каждого AI-ассистента изолирована от других ассистентов на платформе — ваш контент не смешивается с данными других аккаунтов.
Ainisa также работает по модели BYOK: AI-вызовы проходят через ваш собственный API-ключ OpenAI или Anthropic по тарифам провайдера — если вы не знакомы с тем, как это устроено, эта статья объясняет BYOK и почему это влияет на ваши расходы.
При загрузке документа или добавлении URL контент обрабатывается и индексируется автоматически. Обновления вступают в силу немедленно. Шага переобучения не существует.
Практический вывод
RAG — это не магия. Это инженерия. Чатбот, обученный на знаниях вашего бизнеса, настолько хорош, насколько хорош предоставленный контент, насколько качественна система поиска под капотом и насколько точны инструкции, определяющие использование найденного ИИ.
Бизнесы, получающие максимум от AI-чатботов, относятся к базе знаний как к живому документу: добавляют контент, когда вопросы остаются без ответа, улучшают чёткость, когда ответы расплываются, и расширяют охват по мере роста бизнеса.
ИИ справится с остальным.
➤ Попробуйте Ainisa бесплатно — без привязки карты ➤ Читайте документацию Ainisa ➤ Тарифы Ainisa